












 互动量:382
互动量:382
最近总有人问:“我就跑个10亿参数量的模型,4080够不够?非要上4090吗?”其实不少朋友在部署中小型模型时,都会卡在4080和4090的选择上——选贵的怕浪费,选便宜的又怕性能不够。
今天小编就用实测数据说话,在天罡智算平台(https://tiangangaitp.com/gpu-market)租了这两款卡,从参数到实际场景好好对比一番,帮你省钱又省心。
性能参数对比
对比项 |
RTX5090 |
RTX4090 |
NVIDIA架构 |
Blackwell |
AdaLovelace |
显存 |
32GBGDDR7 |
24GBGDDR6X |
显存位宽 |
512位 |
384位 |
显存带宽 |
1.8TB/s |
1.01TB/s |
CUDA核心数 |
21760 |
16384 |
Tensor核心数 |
680 |
512 |
CUDA核心FP16 |
104.8TFlops |
82.58TFlops |
Tensor核心FP16 |
419TFlops |
330.3TFlops |
Tensor核心FP4 |
3352TOPS |
不支持 |
核心差异在哪?
从参数看,4090的优势集中在“量大”:显存多8GB,CUDA核心多6000+,带宽高近300GB/s。这意味着什么?
显存方面:4080的16GB对付7B、13B模型(比如LLaMA2-13B)完全够用,但如果是20B以上模型(比如Mistral-30B),16GB显存就容易“爆内存”,必须靠模型分片或量化压缩,而4090的24GB能直接单卡加载。
算力方面:跑相同的13B模型微调,4090比4080快30%左右。但如果是5B以下的小模型,两者速度差距会缩小到10%以内——这时4080的性价比就凸显了。
该怎么选?看场景!
必须使用5090的模型和场景
模型和场景 |
模型名称 |
关键的性能要求 |
4090的局限 |
参数量超过100亿的AI模型 |
LLaMA3-70B的量化版本 |
显存需求>24GB |
单卡无法加载模型 |
千亿参数量的模型,但只激活了百亿参数 |
DeepSeek-V3只激活37B参数 |
显存需求>24GB,和高显存带宽 |
至少需要2张卡,单卡无法加载 |
8K+图像/视频生成 |
StableDiffusionXL2.1 |
大显存用于缓存中间特征 |
24GB显存无法缓存高分辨率的中间特征 |
FP4精度计算场景 |
FLUX.1图像生成模型 |
使用FP4精度计算,可将模型显存占用压缩50%(相比FP16) |
不支持FP4,无法享受压缩产生的加速收益 |
多模态模型的实时推理 |
Cosmos世界模型, RTXNeuralFaces |
使用FP4精度计算和1.8TB/s带宽,可以实时处理视频流 |
带宽不足导致卡顿,无法实时推理 |
租用流程小贴士
在天罡智算平台,4080和4090的租用流程和5090类似:注册登录后点“弹性GPU”,就能看到两款卡的资源。目前4080的时费是0.79元/卡时(夜间半价更划算),4090是1.04元/卡时,支持1-8卡灵活挂载,预装了PyTorch、TensorFlow等框架,上手就能用。
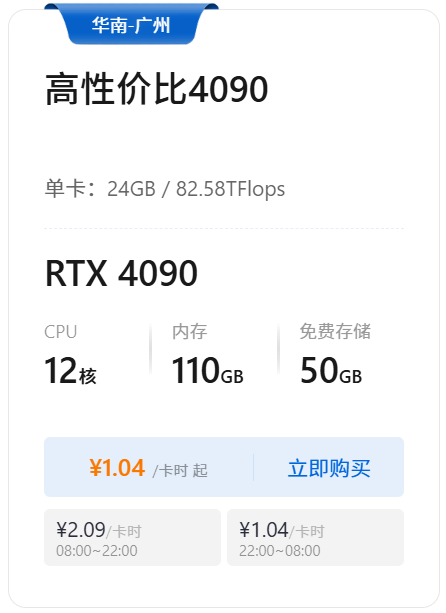
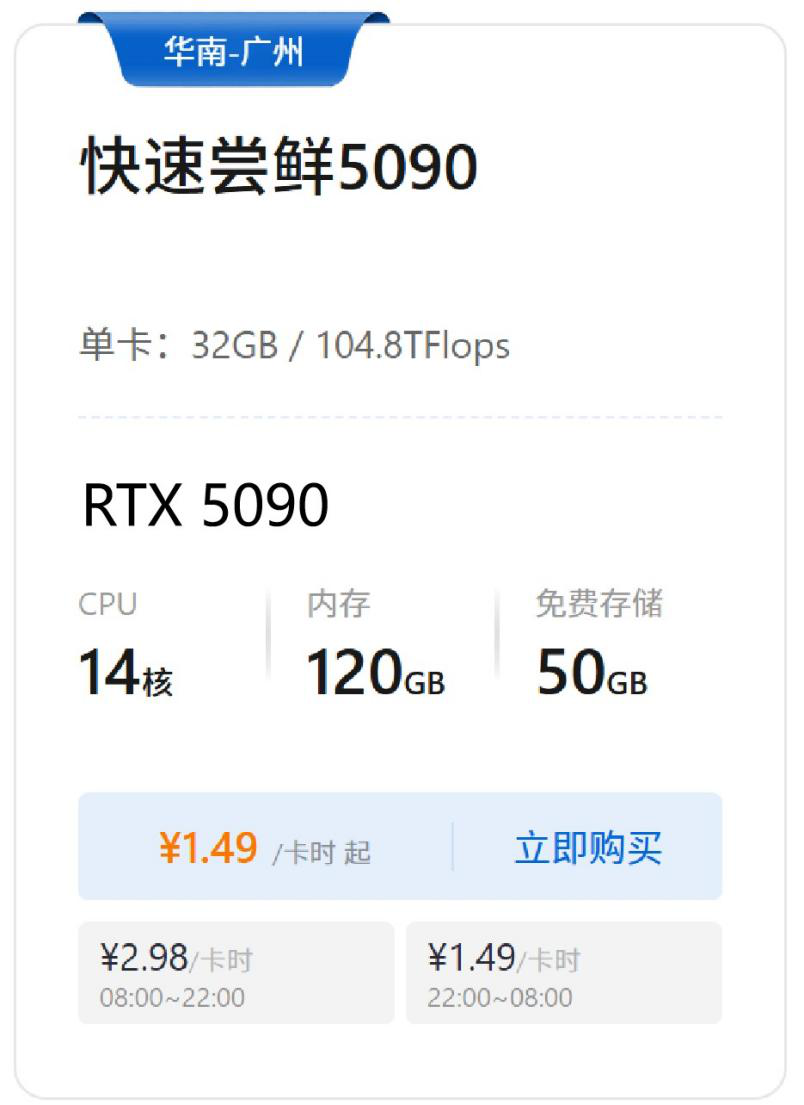
简单说:小模型、低分辨率任务选4080,省钱够用;大模型、高负载任务选4090,一步到位。你部署的模型属于哪类?评论区告诉我,帮你算更精准的成本~












登录 或 注册 后才可以进行评论哦!