












 互动量:31
互动量:31

决策树是一种基于树状结构来进行决策的模型,被广泛用于分类和回归问题。它通过对输入数据集进行逐步的划分,从而在叶节点上做出决策。每个内部节点表示一个属性或特征,每个分支代表该属性或特征的一个可能的取值,而每个叶节点表示一个类别标签或回归值。
决策树的优点是简单易懂,可以直观地表示决策过程。缺点是决策树可能过于复杂,难以解释。
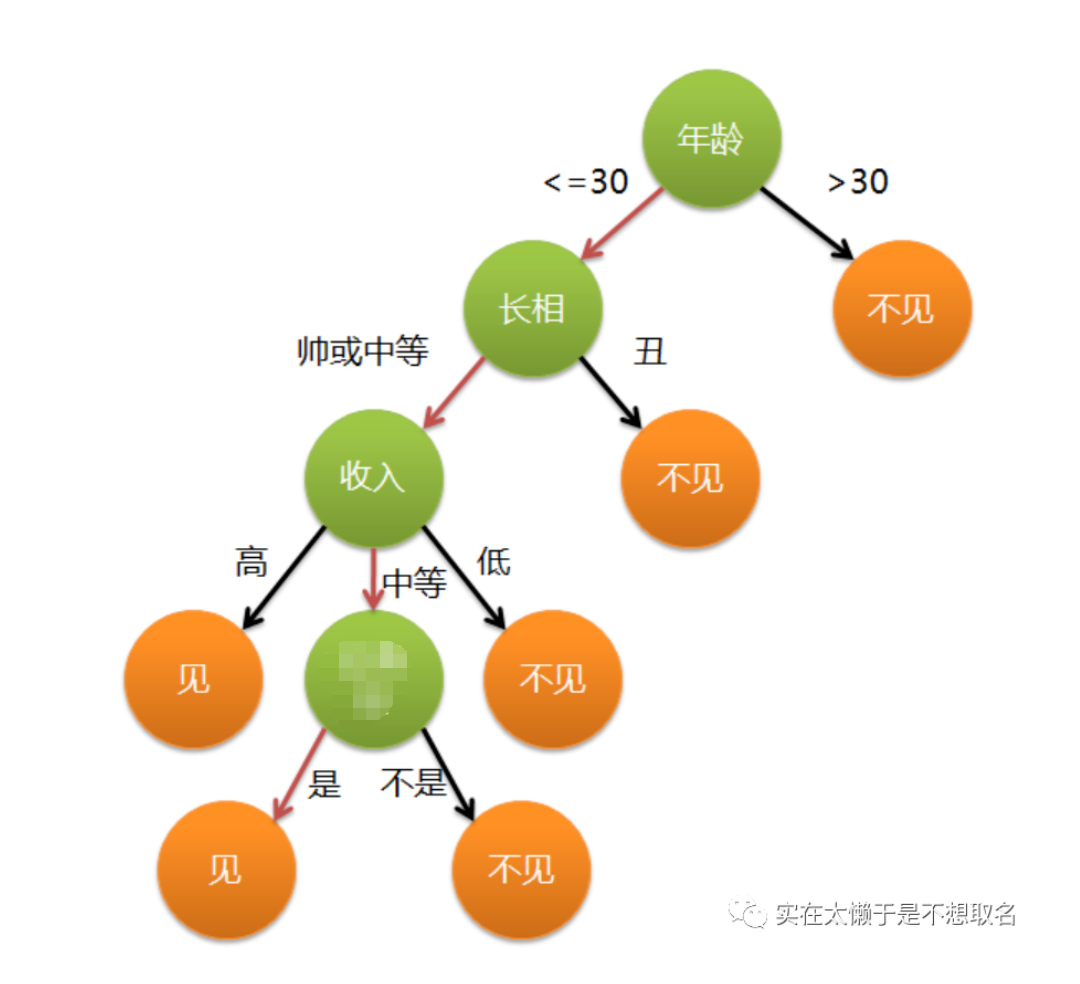
信息增益(information gain)是决策树算法中的一个重要概念,它用于选择最能划分数据集的属性。信息增益是指划分数据集后,数据集的熵(不确定性)减少的程度。
熵是信息论中的一个概念,它用来度量随机变量的不确定性。熵越高,表示随机变量的不确定性越大。
信息增益的公式如下:
信息增益 = 原始熵 - 条件熵
其中,原始熵是指未划分数据集的熵,条件熵是指根据属性划分数据集后,每个子集的熵。
例如,假设我们有以下数据集:

该数据集共有两种属性:年龄和类别。年龄有两个值:小于30岁和大于30岁。类别有两种值:感冒和流感。
原始熵可以计算为:
原始熵 = -(1/2 * log2(1/2) + 1/2 * log2(1/2)) = 1
根据年龄将数据集划分为两个子集:

其中,小于30岁子集包含一个数据点,类别均为感冒。大于30岁子集包含一个数据点,类别均为流感。
条件熵可以计算为:
条件熵 = -(1 * log2(1) + 1 * log2(1)) = 0
因此,信息增益可以计算为:
信息增益 = 原始熵 - 条件熵 = 1 - 0 = 1
信息增益越大,表示属性对数据集的划分越有效。因此,在决策树算法中,我们会选择信息增益最大的属性作为划分数据集的依据。
信息增益的优点是简单易懂,计算方便。缺点是容易受到数据集分布的影响。例如,如果数据集中的某个类别占比过高,那么信息增益可能会被夸大。
ID3算法是决策树算法的一种,它使用信息增益来选择最能划分数据集的属性。信息增益是指划分数据集后数据集的熵(不确定性)减少的程度。
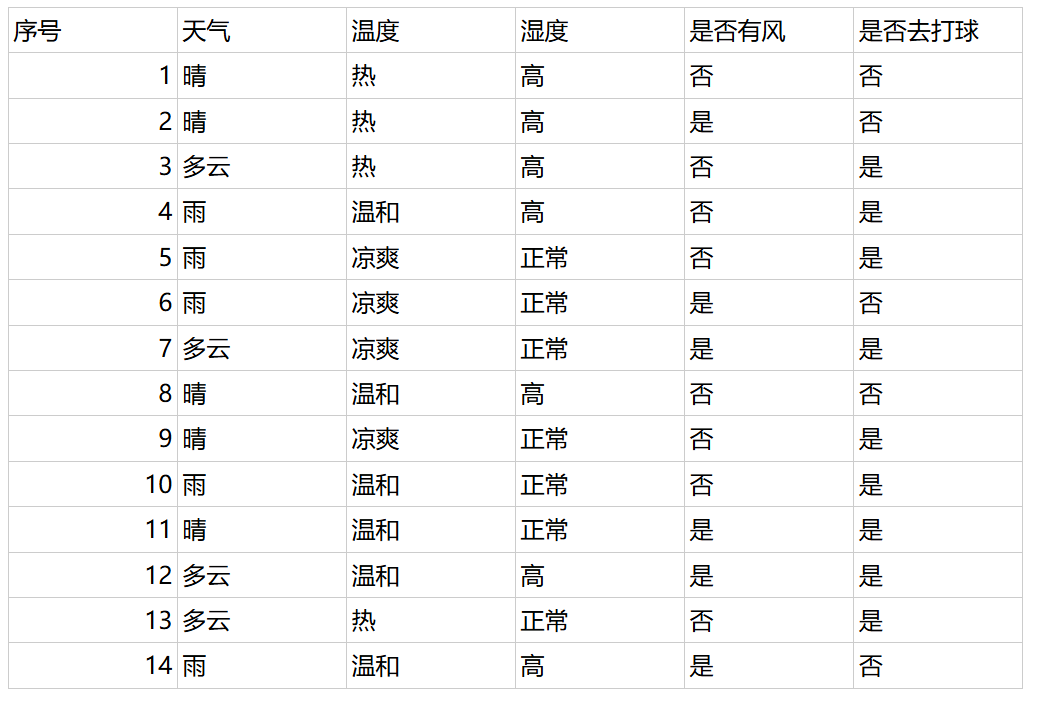
信息增益的公式如下:
信息增益 = 原始熵 - 条件熵
其中,原始熵是指未划分数据集的熵,条件熵是指根据属性划分数据集后,每个子集的熵。
在本例中,原始熵可以计算为:
原始熵 = -(11/14 * log2(11/14) + 3/14 * log2(3/14)) = 0.940
根据天气将数据集划分为两个子集:晴天和非晴天。
晴天子集包含 5 个数据点,其中 3 个数据点的类别是“否”,2 个数据点的类别是“是”。因此,晴天子集的条件熵可以计算为:
条件熵 = -(3/5 * log2(3/5) + 2/5 * log2(2/5)) = 0.609
因此,根据天气划分数据集的信息增益可以计算为 信息增益 = 0.940 - 0.609 = 0.331
同样,我们可以计算出其他属性的信息增益。
因此,我们选择天气作为第一个分类属性,因为它的信息增益最大。
属性信息增益天气0.6931471806温度0.4138067639湿度0.3258092328是否有风0.1921568627
根据信息增益的值顺序,我们可以列出我们的分类图
天气-->温度-->湿度-->风力
例如:
非晴 凉爽 正常 无风 去打球













登录 或 注册 后才可以进行评论哦!
还没有评论,抢个沙发!