












 互动量:571
互动量:571
众所周知,我们要在单片机中对一个数据进行预测并不是一件简单的事情。例如上周学弟给了我一组数据,数据由三组输入数据组成,输出一个数据。
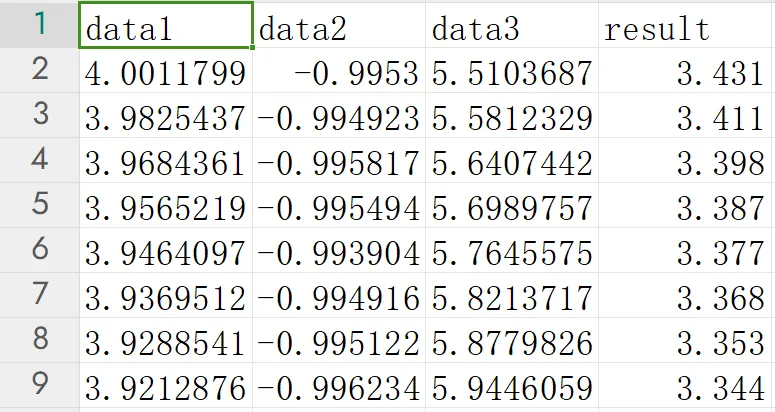
三组输入数据是来自传感器的输入值,希望我用单片机(STM32H7)来预测一下输出值。
正常这种情况我可能会选用Matlab,不过拟合工具中只支持双变量输入,单变量输出,显然我们不能直接使用Matlab的曲线拟合工具。
Matlab拟合的原理是基于最小二乘法,即通过最小化模型预测值与实际数据点之间的误差来确定拟合参数。为了解决这个问题,于是我就想到了机器学习。
前几日我们利用Python训练了一个手写数字识别的模型,并利用CubeAI部署到STM32中。
那么既然已经掌握了CubeAI部署机器学习模型的方式,我们为什么不利用机器学习做一个三变量输入,单变量输出的神经网络呢?。于是我想到了多重感知机。
它是一种前馈型人工神经网络,利用加权计算和反向传播机制训练,通过增加隐藏层和神经元的数量,逼近任意的非线性函数,理论上它是一个强大的逼近器。非常适合我们解决这个问题!
于是我们利用Tensorflow来训练一个预测模型。(Py的源码放到了最后,有点长)包含了数据提取,数据的输入(开始把数据放大了怕精度损失,后来就恢复了)还有模型测试。
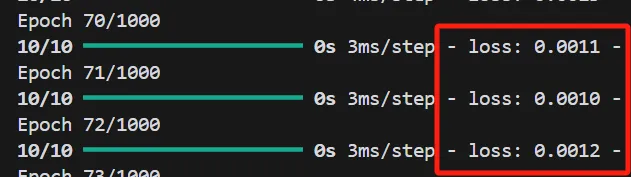
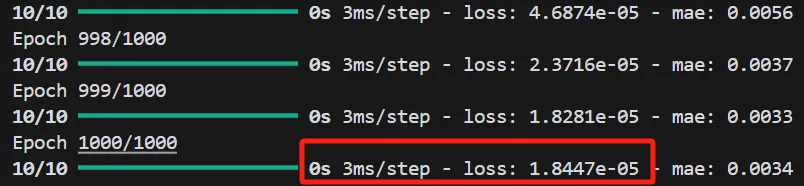
可以看到,随着训练轮数的增加,损失函数降低到了0.0012。

最后模型预测也是非常完美。接着我们利用CubeAI将我们保存好的TFLite文件导入到STM32工程中。
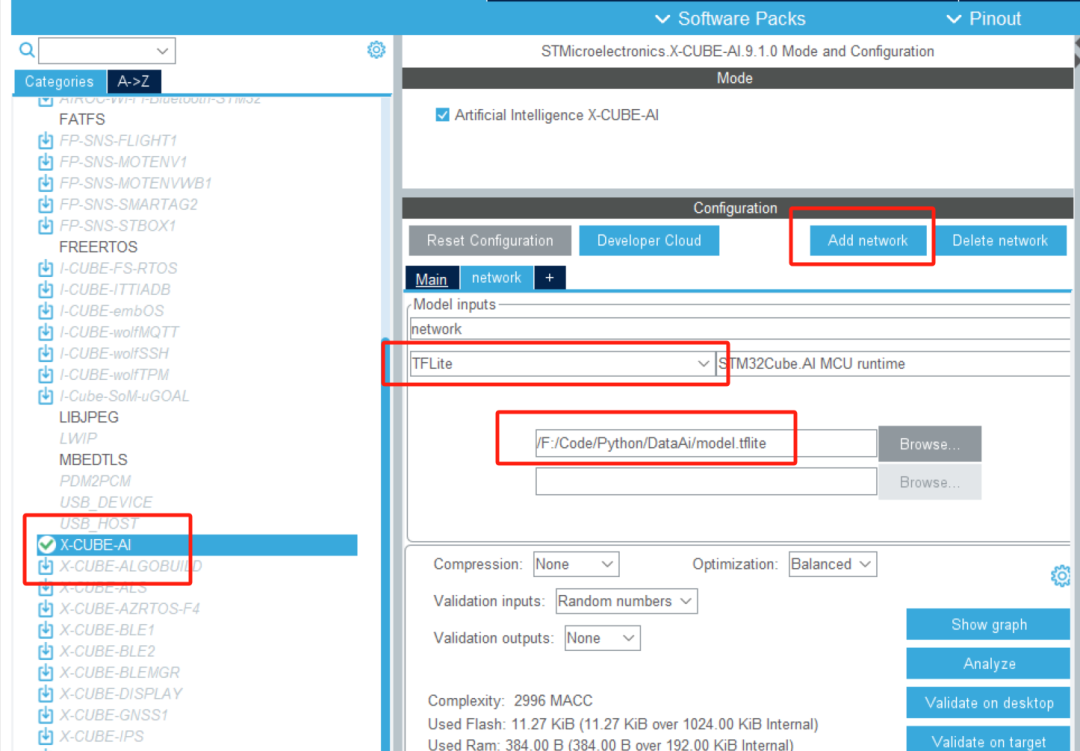
在CubeAI中选择我们的模型,并且分析(Analyze)
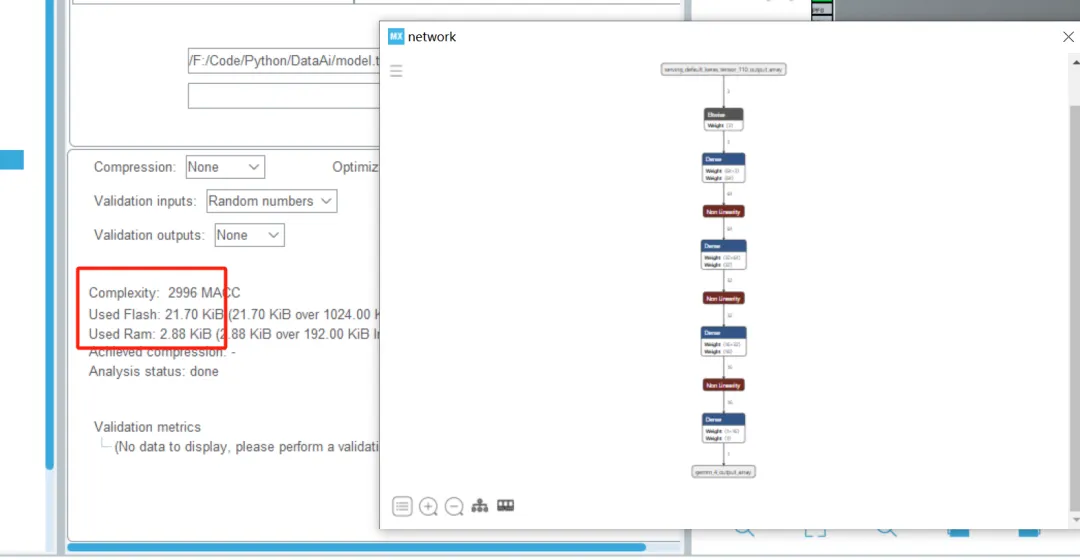
这里可以看到我们的网络结构和占用的单片机内存大小,可以看到空间也是非常的笑,只有21KB的FLASHh和3KB不到的RAM。可以说是非常的小了。
分析完的模型,就可以生成工程了。
#include "network.h"
#include "network_data.h"
static ai_handle network = AI_HANDLE_NULL;
AI_ALIGNED(32)
static ai_u8 activations [AI_NETWORK_DATA_ACTIVATIONS_SIZE];
AI_ALIGNED(32)
static ai_float in_data[AI_NETWORK_IN_1_SIZE];
AI_ALIGNED(32)
static ai_float out_data[AI_NETWORK_OUT_1_SIZE];
static ai_buffer *ai_input;
static ai_buffer *ai_output;
int aiInit(void) {
ai_error err;
/* Create and initialize the c-model *//*?c-model */
const ai_handle acts[] = { activations };
err = ai_network_create_and_init(&network, acts, NULL);
if (err.type != AI_ERROR_NONE) { };
/* Reteive pointers to the model's input/output tensors *//*???/?*/
ai_input = ai_network_inputs_get(network, NULL); ai_output = ai_network_outputs_get(network, NULL);
return 0;
}
int aiRun(const void *in_data, void *out_data)
{
ai_i32 n_batch;
ai_error err;
/* 1 - Update IO handlers with the data payload *//* 1 -IO*/
ai_input[0].data = AI_HANDLE_PTR(in_data);
ai_output[0].data = AI_HANDLE_PTR(out_data);
/* 2 - Perform the inference *//* 2 -*/
n_batch = ai_network_run(network, &ai_input[0], &ai_output[0]);
if (n_batch != 1)
{
err = ai_network_get_error(network);
HAL_GPIO_TogglePin(GPIOF,GPIO_PIN_10);
};
return 0;
}
依照官网的示例代码编写启动和运行函数。
aiInit(); in_data[0] = 3.95652185f; in_data[1] = -0.995493751f; in_data[2] = 5.698975728f; aiRun(in_data, out_data);
接着便可以测试我们的模型拟合是否和实际结果接近了。


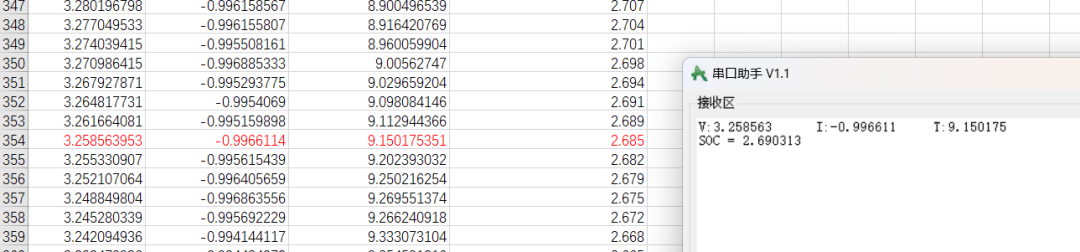
可以看到四次实验的结果误差分别在:
0.0014,0.0006,0.0005,0.0012,分别是万分之四,万分之二,万分之二,万分之四,平均万分之三的误差!
非常的接近真实值!
Py源码:
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import joblib
def load_data():
df = pd.read_csv('AI_data.csv')
INPUT_SCALE = 1 # 输入放大
OUTPUT_SCALE = 1 # 输出放大
df['data1'] = df['data1'] * INPUT_SCALE
df['data2'] = df['data2'] * INPUT_SCALE
df['data3'] = df['data3'] * INPUT_SCALE
# 放大输出数据
df['result'] = df['result'] * OUTPUT_SCALE
for column in df.columns:
print(f"{column}: {df[column].min():.2f} to {df[column].max():.2f}")
return df
def prepare_data(df):
X = df[['data1', 'data2', 'data3']].values
y = df['result'].values
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test, scaler
def create_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(64, activation='relu', input_dim=3, name='dense_1'))
model.add(tf.keras.layers.Dense(32, activation='relu', name='dense_2'))
model.add(tf.keras.layers.Dense(16, activation='relu', name='dense_3'))
model.add(tf.keras.layers.Dense(1, name='output'))
model.compile(
optimizer='adam',
loss='mse',
metrics=['mae']
)
return model
def train_model(model, X_train, X_test, y_train, y_test):
history = model.fit(
X_train, y_train,
validation_data=(X_test, y_test),
epochs=1000,
batch_size=32,
verbose=1
)
return history
def save_model(model, scaler):
scale = scaler.scale_
mean = scaler.mean_
input_layer = tf.keras.layers.Input(shape=(3,))
norm_layer = tf.keras.layers.Lambda(
lambda x: (x - mean) / scale
)(input_layer)
output = model(norm_layer)
complete_model = tf.keras.Model(inputs=input_layer, outputs=output)
converter = tf.lite.TFLiteConverter.from_keras_model(complete_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float32]
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
print("模型已保存为 'model.tflite'")
print("\n标准化参数:")
print("Mean:", mean)
print("Scale:", scale)
return complete_model
def test_model_prediction(model, scaler):
"""测试模型预测"""
# 放大倍数
INPUT_SCALE = 1
test_data = np.array([[3.982543688, -0.994922547, 5.581232859]]) * INPUT_SCALE
expected_result = 3.411 * 1
X_scaled = scaler.transform(test_data)
pred_original = model.predict(X_scaled)
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], test_data.astype(np.float32))
interpreter.invoke()
pred_tflite = interpreter.get_tensor(output_details[0]['index'])
def main():
# 加载数据
df = load_data()
X_train, X_test, y_train, y_test, scaler = prepare_data(df)
model = create_model()
history = train_model(model, X_train, X_test, y_train, y_test)
complete_model = save_model(model, scaler)
test_model_prediction(model, scaler)
if __name__ == "__main__":
main()
 #includenetwork.h#
#输入放大OUTPUT_SCALE=1#
#includenetwork.h#
#输入放大OUTPUT_SCALE=1#













登录 或 注册 后才可以进行评论哦!
还没有评论,抢个沙发!